AI-Transformer学习
基础了解
函数解释万物:符号主义
把世间万物的联系都用一个函数联系
有输入,放入函数,得到输出
但是到头了,因为人类很多时候无法总结出一个函数来描述
近似逼近函数:联结主义
通过简化函数,找到接近真实函数的近似解
比如一堆点,可以找一条近似的直线,而不是一条复杂无比的曲线
激活函数
把线性函数变为非线性函数,比如加个sin,变成e的幂等等
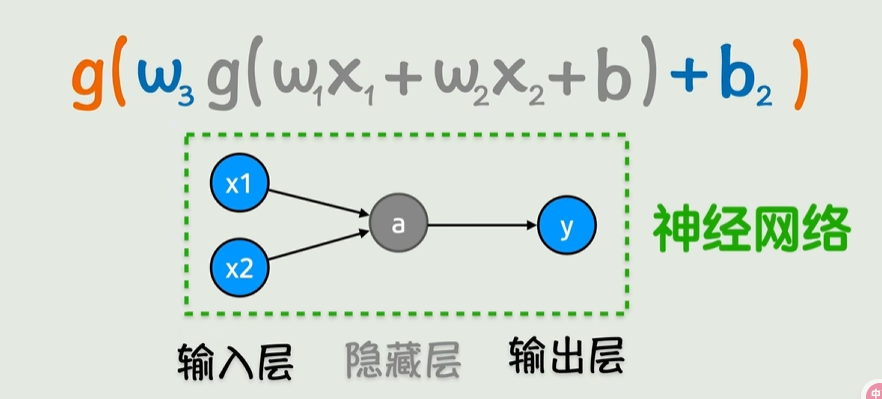
神经网络
输入层两个x1,x2;
线性变化+激活函数,得到隐藏层;
再线性变换+激活函数,得到输出层;
一层层嵌套,像是箭头不断向右,这就是神经网络的前向传播
损失函数
表示真实值和预测值的偏差
最小二乘法回归分析
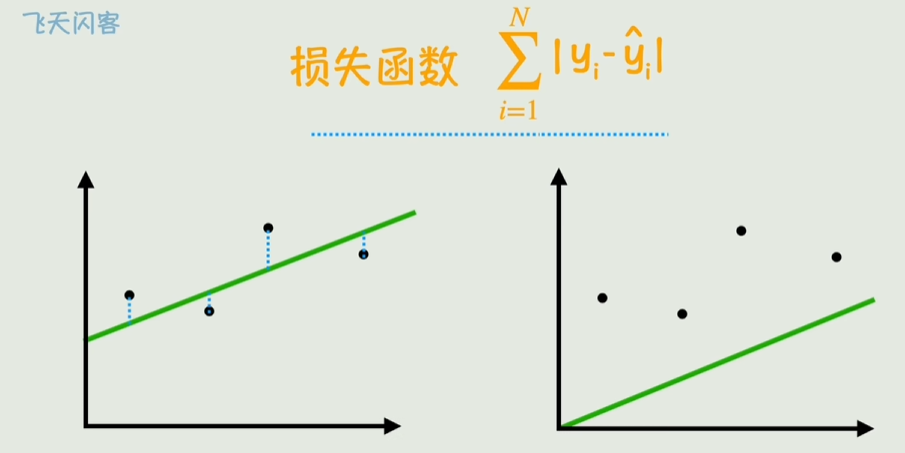
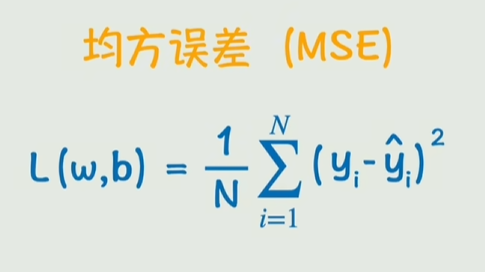
所要做的就是让损失函数尽可能逼近0
现在的方案就是不断尝试进行逼近直到足够小
求出最小的w和b的过程就是梯度下降
通过每次损失函数计算w和b,然后左一次接着右一次计算
就相当于不断向左传播w和b,称之为反向传播
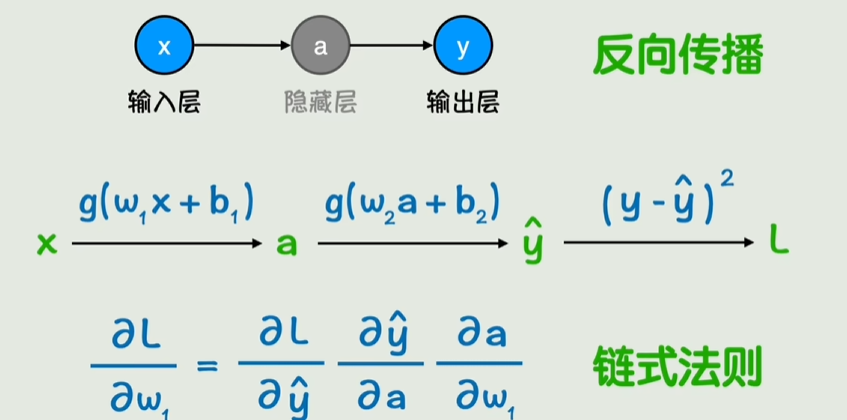
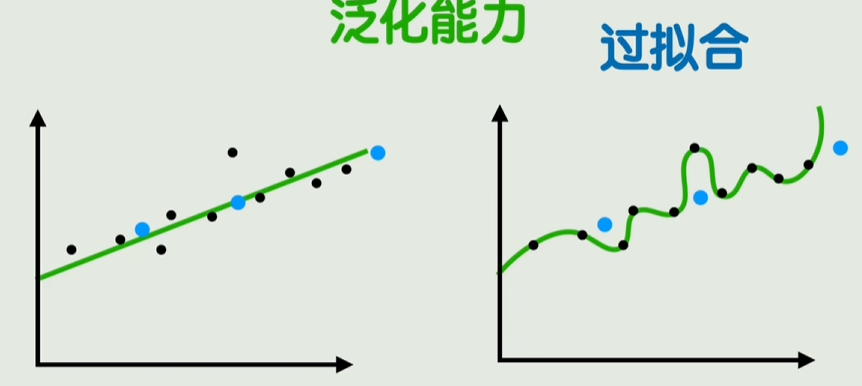
过拟合/泛化能力/惩罚项/正则化/Dropout
通过控制训练过程的数量和时长,防止过拟合
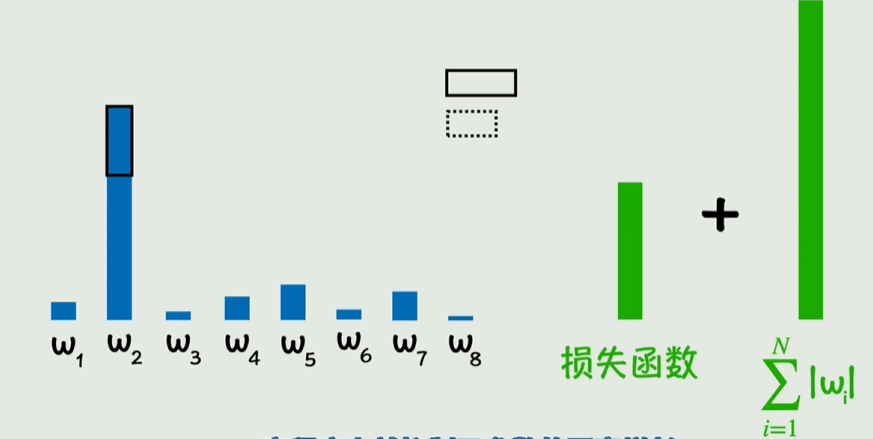
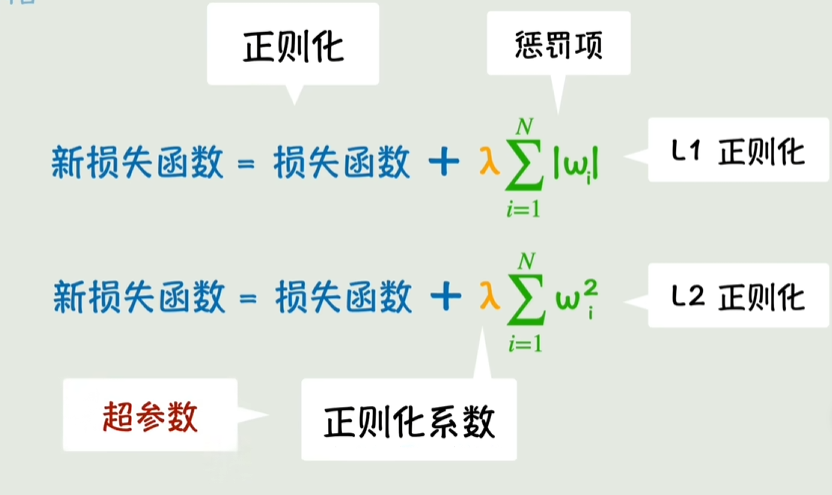
惩罚项,正则化
通过损失函数加上某个值,如果w增长快,会导致惩罚项-损失函数值>0,此时抑制增长
Dropout,通过随机丢弃一部分参数来训练,避免过度依赖某些小部分参数
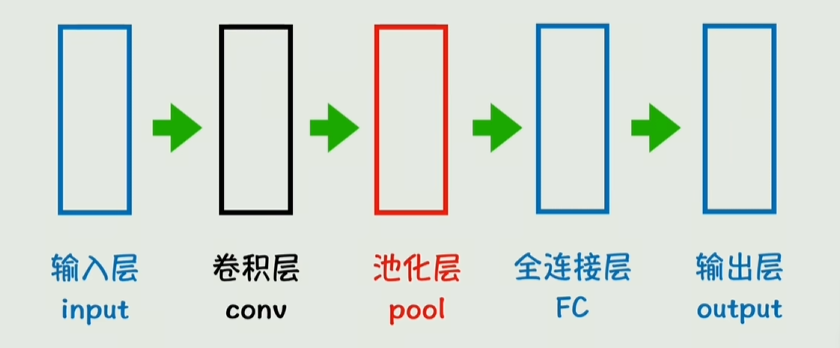
矩阵和CNN
矩阵略
卷积核,卷积运算略
深度学习领域,卷积层是计算出的一层参数
适用于图像识别领域的叫卷积神经网络CNN
RNN到Transformer
词嵌入:把文字转化为一个多维的向量
通过点积和cos得到特征

嵌入矩阵:每个词的向量合并
RNN
通过每个词的矩阵和权重矩阵相乘,不断计算隐藏状态并向前传递
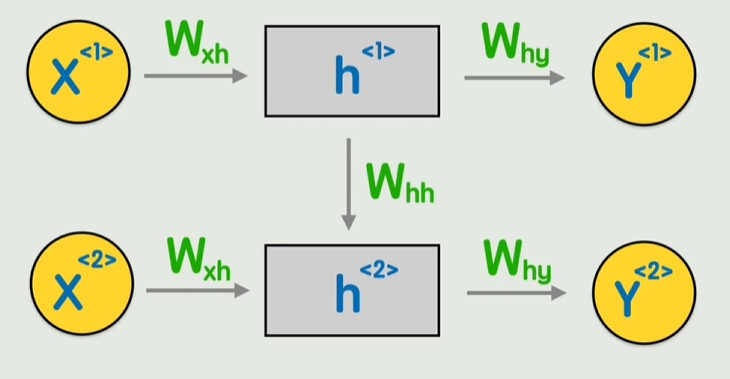
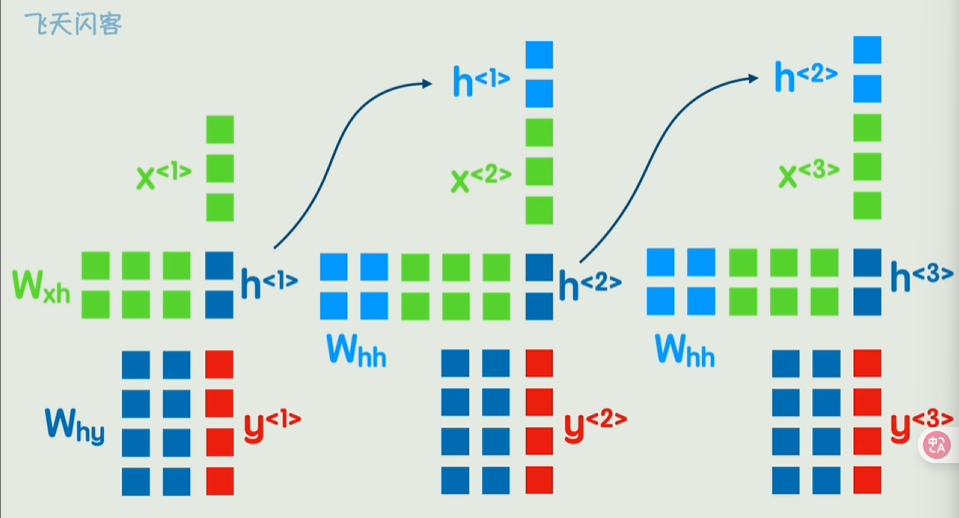
Transformer架构
RNN会有串行计算,长期依赖困难的问题
Transformer
- 给每个词加上位置信息:也就是位置矩阵叠加本身词的转化矩阵
- 权重值Wq,Wk,Wv分别和词相乘,得到向量
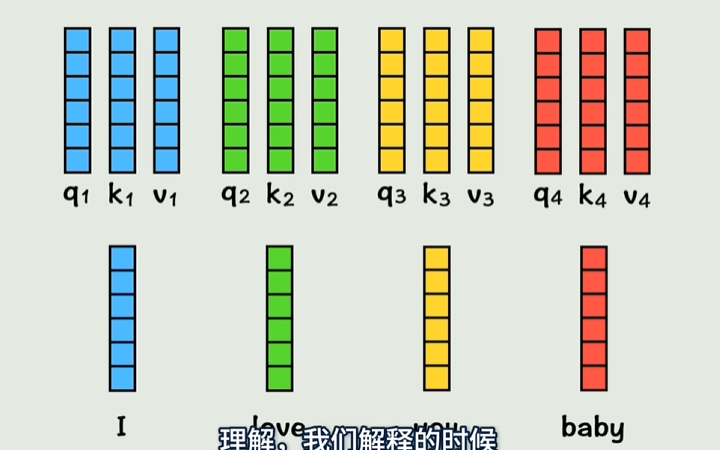
通过每个q和不同的k计算得到相似系数a
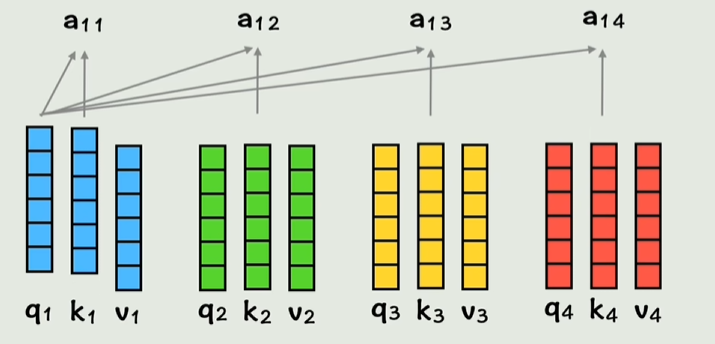
不同相似系数*v相加,这样相当于把不同词的上下文信息都存到新向量里了
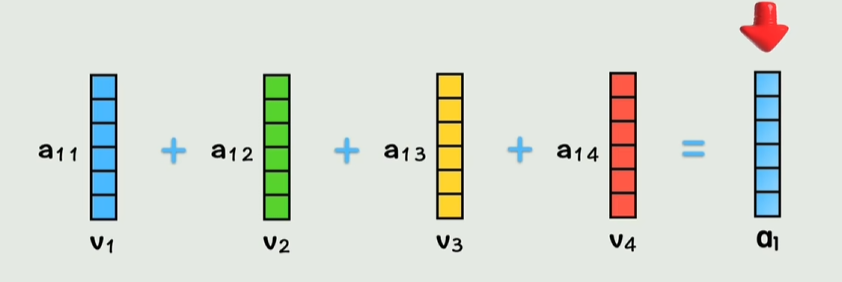
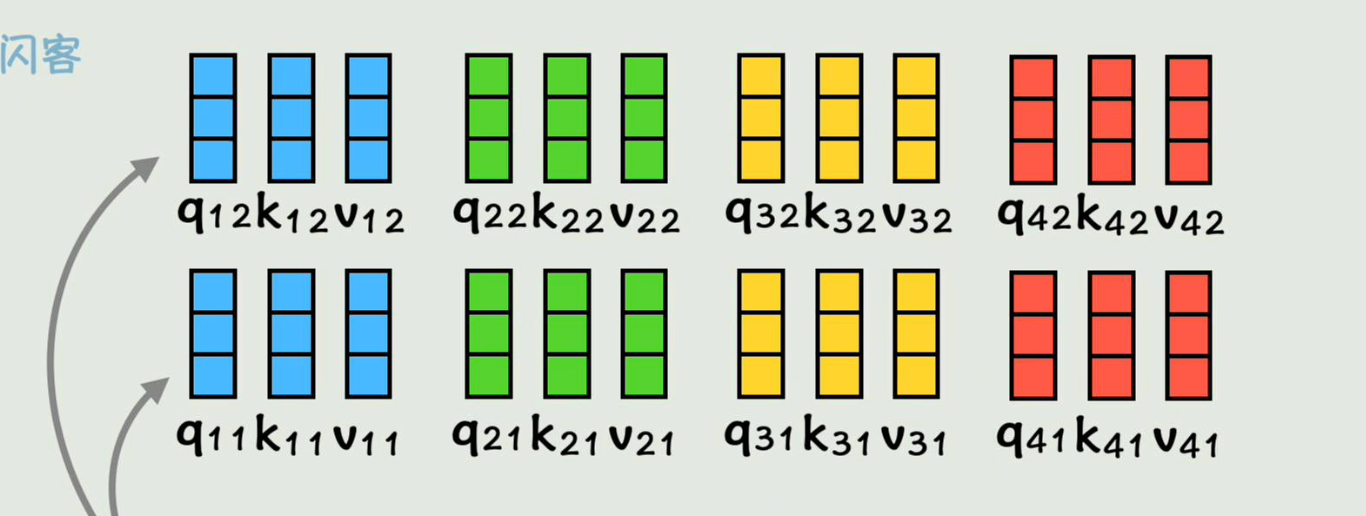
不断用不同权重矩阵重复3和4步骤然后叠加,得到多头注意力
把两组小a拼起来依旧组成一个六维向量,就是双头注意力
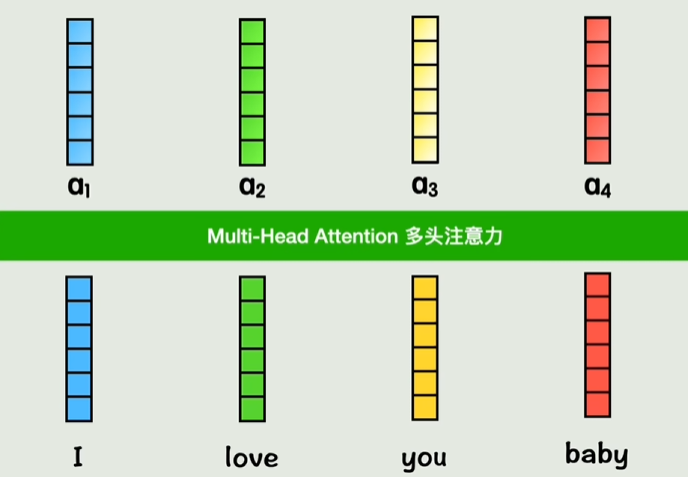
AI-Transformer学习
http://example.com/2025/05/01/AI-Transformer学习/